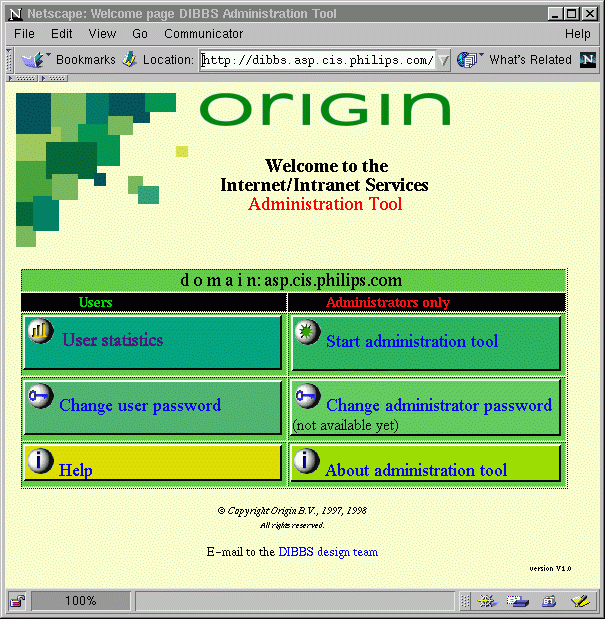
Fig. 1, Local administrator web start page. Users can find help and personal statistics here too and can change their password. This image is from our Asia Pacific (ASP) IntraConnect.
In this paper we present a methodology for handling software that can be used to outsource intranet services. We call this software 'outsourceware'. We present our general oursourceware philosophy and show how it is used in our intranet server implementation.
Within Origin, Technical Infrastructure Services (TIS) is the part of the company doing day-to-day operations of all services, ranging from Network Services (TCP/IP and SNA) to Mainframe Processing Services. Within TIS, the Intranet Services (INS) division (currently approximately 100 people) delivers Internet and Intranet related services on a world-wide scale: SMTP, DNS, mail gateways, IP/SNA gateways, FTP/WWW hosting, Usenet News, firewall/security services, dialin services, and various types of proxy services. Our largest customer is still Philips (for historical reasons of course) but we have started providing Intranet services for other customers as well.
The servers in use at that time were all located in Eindhoven and built as prototypes without a global roll-out and without customers other than Philips in mind; some of these servers were legacy systems inherited by Origin. We needed to standardize and redesign our services in order to accomodate our customers' generic demands and to realize the scalability needed.
From a customer point of view we need services that :
With the strong requirements in mind we started designing our own implementation, which started under the initial project name 'DIBBS': Distributed Intranet Black Box Server. The reason for calling it a black box was that the customer should consider it a black box, although it should be a crystal clear box to ourselves. Later on DIBBS was changed to the commercial name IntraConnect.
In each of the following 5 chapters we first present general outsourceware remarks and requirements, and then explain the IntraConnect implementation.
The second method can deal quickly with changes, but experience shows that services will diverge at all service locations because of different administration methods.
A third way of dealing with global services is to implement what we call 'split administration'. In this scheme we keep local things local and central things central. Because the central things are normally done from a remote location we started using the term remote administration for this and we will use this term in the remainder of this paper.
Fig. 1, Local administrator web start page. Users can find help and personal statistics here too and can change their password. This image is from our Asia Pacific (ASP) IntraConnect.
Additionally, the local administrator performs those tasks that require physical access to the server. This includes replacing hardware in case of failures, and tape management for backup purposes.
The remote administrators (normally a group of people) do the remote service management on a global scale. The idea is to automate the remote administration tasks as far as possible, and to store information just once. Standard tasks include enabling and disabling a service for a specific server, reconfiguring a service, upgrading the service software, etc.
IntraConnect implements these tasks such that they do not require intervention from a remote administrator on the server itself, as they are automated via a central distribution server. But if needed these tasks can be performed via an extended version of the GUI that the local administrator uses or by logging on to the server. Unlike local administrators, remote administrators can logon to the servers for example, to troubleshoot difficult problems which cannot be diagnosed (or not fast enough) via a web-based GUI.
Currently, the group of remote administrators consists more or less of the group of people doing the IntraConnect development. This will certainly change when more and more servers are rolled out.
The API must contain certain generic functions like 'start', 'stop', 'check', 'reconfigure', 'install', 'backout' and 'remove'. These must be implemented for each module, possibly as a 'stub' operation. The software packages own methods of starting, etc. should not be used directly anymore.
Not all modules will be on the same level as some will have a general or support function for the other modules. This will result in some kind of module hierarchy.
The main advantages of modularization are:
A disadvantage of this approach is that we changed all the software packages file locations from where they are usually located on a UNIX system. In return we get a service oriented directory structure. Underneath that structure, the standard UNIX directory structure was preserved. We found that new people to our project understood this setup quite fast.
The real configuration files that the service software uses are generated from three sources:
The binary module contains all binaries, sh/perl scripts, CGI scripts, online documentation (HTML) and those parts of the configuration files which can or must be the same for all servers irrespective of location and customer. Thus, the binary module is the same for all servers (given one OS). A typical binary module is a 100 KB gzipped tar file.
The configuration module contains all parts of the centrally managed configuration specific to one server machine. Examples are IP address, netmask, DNS name servers, etc. A typical configuration module is a 1 KB gzipped tar file.
Modules are stored as gzip compressed tar files. To uniquely identify a module we have added a version identification in YYYYMMDDxx format to the module names. Examples:
general-b.1998071400.tar.gz (Binary module)
general-c.1998071003.tar.gz (Configuration module)
This naming convention with version numbers is used by the automated
distribution and upgrade mechanism to decide whether a new release
of a module is available. This will be discussed later.
|
The operating system module. This is a stripped down version
of the OS containing only those programs really necessary.
In case of IntraConnect on BSD/OS the OS has been stripped
down to only 6.2 Mbytes (gzipped). The reason for using a
stripped down version is that it makes automated OS installs
over small-bandwidth network connections possible; furthermore
it is easier to make secure.
The OS module consists of a binary part only. All configuration
files in |
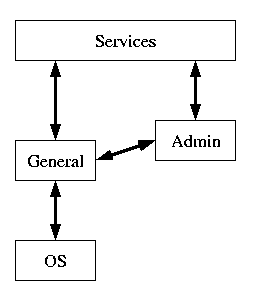
Fig. 2, Module hierarchy. |
Upgrading to a new OS release involves upgrading the development server and generating a new OS module, of course taking care that binaries from other modules for the older OS release can still be run by installing backward compatible shared libraries. When a major OS release is involved, extra actions may be necessary in the OS installation scripts.
/etc.
The most important configuration file is the master.root file. It contains all generic parameters like IP addresses, netmasks, extra DNS servers, trusted hosts for the web-based GUI and telnet/ssh, etc. It contains variable/value pairs and may only be read by two include files, one for /bin/sh scripts, one for perl scripts. These include files can also be used for all kinds of backward compatibility tricks, this will be shown in the section about multi machine IntraConnect later on.
Another important aspect of the master.root file is that items like IP numbers are stored only once. Other configuration files needing these parameters must retrieve them from this master.root file by scripts. In the past, moving a machine to another IP addresses caused lots of trouble because of the large number of different configuration files containing one and the same IP address.
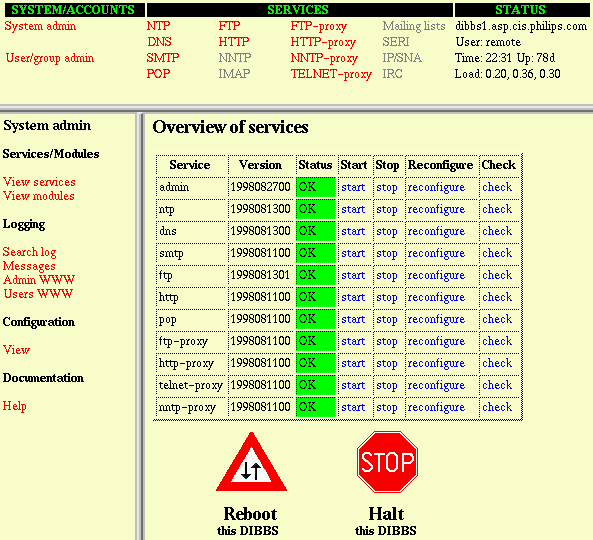
Fig. 3, Administrator example of the services overview. The three frames showed come from the general module.
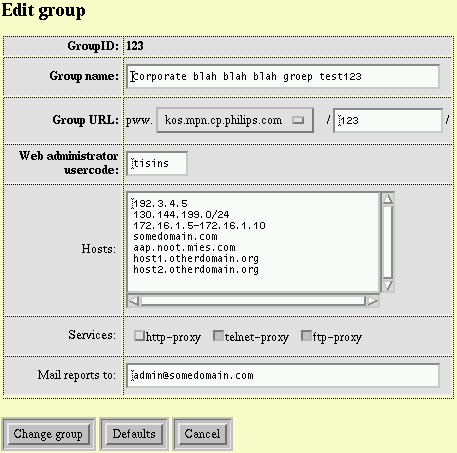
Fig. 4, Flexible group definition example. Note the various 'Hosts' entries. The Services list is automatically expanded when new services become available.
The admin module on IntraConnect deals with fine-grained access control, up to services per individual (see Fig. 5 and Fig. 6). The reason for this fine-grained access control is that not every company allows all of its employees to access all public Internet services. The database of the admin module is used by other services to generate access files for those particular services.
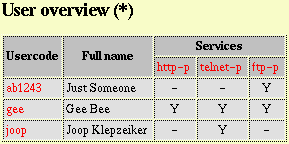
Fig. 5, Flexible user service permissions example.
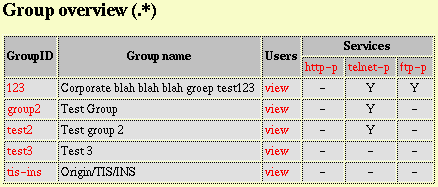
Fig. 6, Flexible group service permissions example.
The admin module also provides detailed accounting and reporting information which is very important for an outsourcing company like Origin. In the case of Philips, Origin deals with lots of different product division and business units each of which get their own bills based on, for example, megabytes transferred.
The ntp service is implemented using the xntpd distribution. The remote configuration consists only of a list of servers and peers. Fig. 7 shows an example of the NTP service status frame.
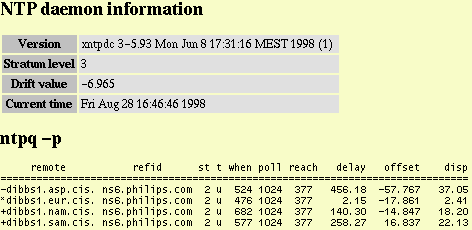
Fig. 7, NTP daemon server status example.
The dns service is implemented using the bind distribution (version
8). The configuration part consists of two files,
primaries and secondaries in very simple
formats, and DNS zone files (without the SOA part) in the case
of primary zones. From these files a named.conf file is generated
and complete zone files with a correct SOA record containing an
automatically maintained serial number are generated.
The smtp service is currently implemented using sendmail 8.8.8.
A script generates an M4 file from master.root information and
some additional configuration files. Then, using the normal
sendmail M4 tools, the real sendmail.cf is generated. If users
are defined in the admin module, the script will generate the
appropriate aliases, virtusertable and userdb files and their
.db versions. The smtp service can handle multiple
mail domains per server machine.
All these proxies have been socksified to work with the socks-based firewalls managed by Origin. At Origin we separate machines for network perimeter security and proxy servers to keep the bastion hosts of the firewall as simple as possible: no users, no accounting, etc.
Access files are generated using the user/group database from the admin module. Because the admin module allows almost every possible DNS domain and network slice notation, some entries like 192.168.2.32/27 get expanded into multiple IP addresses for the telnet, ftp and nntp proxies which do not support these notations.
During development we move scripts or routines from a normal service module to the general module as soon as that script or routine is necessary in other modules too. This way a lot of duplicate coding is avoided when adding new services. This also matches our 'store everything once' approach for configuration items.
/usr/local/bin/,
/usr/local/etc/, etc. but each module has its
own directory tree under /usr/dibbs/, for example,
/usr/dibbs/general/. Below such a tree we have the standard
bin/, etc/ and lib/ directories,
furthermore we added config/, htdocs/
and cgi-bin/. The reasons to do this are easy upgrades
(just move a directory and unpack a new module) and backouts of upgrades
(move the old directory back). It also avoids the need for a detailed
file list per module and makes it possible to have scripts with the same
names for each module.
For a binary module we defined some entry points; the most important
ones are listed below. Filenames are relative to the root of the
module, for example, /usr/dibbs/general/.
VERSION (required for every module)
bin/installer (required)
/tmp creating a
/tmp/general directory. Then 'cd /tmp/general;
bin/installer install' is run. This will stop the current
running service, create a backout copy of the currently installed
module, install the new module in the appropriate directory,
optionally import local configuration files and finally
reconfigure and start itself. All these actions are done in a
non-interactive fashion so that they can be done from cron.
Although all services have their own installer script, most of the installer routines are very generic and are defined in a library in the general module which is used by the installer scripts.
bin/service (required)
A simple way to implement the reconfigure part of the service script is to call the stop routine, regenerate all configuration files and call the start routine. However, for many of the services the reconfigure is done by just regenerating the configuration files and giving the service daemon a signal (normally HUP) to make it reread the configuration files. This leads to less, or no, service interruption.
The service script of the general module has two extra options, startall and stopall to start and stop all other services.
bin/{hourly,daily,weekly,monthly} (optional)
bin/rotate (optional)
cgi-bin/menu.cgi (optional)
config/filter.conf
A first-time installation procedure should be a special upgrade procedure: 'upgrade from nothing'.
For the local administrator, a service backout option (restore the old working situation) should be available as a quick fix for any possible undesirable effects experienced by end-users after an automated change which is solely under remote control.
Upgrades must only be performed in the customers' change window, but in case of problems the local and global service delivery organizations must be informed so they can take the necessary actions needed to solve the problem. Only a few minutes of service interruption should arise in a normal change window.
config.guess script
(for example, i386-pc-bsdi3.0). In this way a distribution server can
support multiple platforms.
As proof of concept, the distribution server has been implemented as a normal FTP server. Minimal security is implemented through a tcp-wrapper. This will be improved and extended in the future as we require more security and a push variant for non-intranet servers; normally the servers can pull the modules from the distribution server but for servers outside the firewall this might not be allowed because of security reasons.
During an automated upgrade, the OS module performs all actions on the
other boot disk. This provides an easy backout possibility;
the advantage of being able to backout an upgrade greatly outweighs the
cost of an extra disk. At the end of the installation of the new OS on
the new disk /usr/dibbs/, /usr/config/ are
copied to the new bootdisk and a fresh general-{b,c} module is saved on
the new disk. Only at the end of the OS upgrade are all services stopped
by calling service stopall and after changing either the server's
boot prom (Suns) or the boot.default configuration file (BSD/OS) to
configure the new boot disk, the system is rebooted.
When the system comes up from the new boot disk it detects the first
boot after an upgrade, installs general-b and general-c (which
configures everything needed in /etc, such as its IP numbers
and hostname), and boots further starting every service with service
startall.
The /var, /news and /cache
partitions are located on separate data disks and thus need not
be copied during an upgrade. The whole OS upgrade can cause up to 4
minutes service disruption; this is highly dependent on the amount of
RAM in the machine which has to be counted during boot (the HP
Netservers we use have slow memory tests).
The service check should be more than just verifying that a given daemon process exists. Proper functioning of a service should also be checked. Useful methods include protocol level questions with known answers, or the typical welcome-to-this-protocol messages.
When the server discovers that something is not functioning properly, it should notify a central monitoring location. Failure in the self-checking functionality of the server will result in loss of the notification. Therefore, the server should send so-called heartbeats to the central monitoring location using the same mechanism. If the self-checking mechanism fails, the loss of heartbeats will be detected by the central monitoring location.
Heartbeat messages are generated from the general module every 15 minutes and are logged via syslog. The heartbeat message contains the current UTC date and time in ISO format.
The syslog file (/var/log/messages) is tracked in real-time
(by a program called follow) and filtered based on regular
expressions (by a program called filter) to service-specific
log files in (/var/log/<modulename>/). Every service has at
least a 'messages' log file for just informative, non-priority messages,
an 'acct' log file for accounting data and 'daily', 'low', 'high' and
'alert' log files for messages of different priority. Any message not
filtered explicitly by a regular expression is directed to the high
priority log file. This forces us to classify any unknown messages in
an appropriate category (daily/low/high/alert). The contents of these
log files are sent to the central monitoring station every 1440 (1 day),
60, 15 and 1 minutes (if there is new data in it of course).
The heartbeat messages follow exactly the same path through the system as the output of the check scripts and the logged events from the services: start from cron, log via syslog, then filtered via follow and filter and put into specific log files and then processed by a script run from cron. We can thus be sure that all critical system processes are operational when we receive heartbeats. If a heartbeat is not received within 30 minutes, the central monitoring station generates an alert message itself. Absence of the heartbeat means that either the self-check mechanism is not working, or that there is a network outage between the IntraConnect server and the central monitoring location.
All heartbeats and logging messages are sent using SMTP to, preferably, the IP address of the central monitoring station. We use IP addresses to prevent dependency on other SMTP hubs. All we need is a properly functioning network between server and monitoring station. We did not want to rely on UDP based services like SNMP traps because of the unreliability of UDP and because of systems outside proxy-based firewalls. Despite the complexity of two SMTP setups, this system has proven to be stable and reliable during the four years that we use it.
Our experiences show that in general we, as a service provider, can react quickly to service problems and that we are sometimes even able to solve problems before the customer detected that there was a problem. Furthermore, the concept can also be used to generate lower priority messages whenever a service interruption is likely to occur in the near future. As an example, we generate messages whenever DNS zone transfers are failing. In itself this is non-critical but if the problem persists, it might lead to a disfunctional DNS service.
Reporting includes all usage statistics not needed for accounting. Reporting needs to be much more detailed per billing unit than accounting. It is sometimes used solely for trend analysis. Most software is capable of generating (huge) logfiles, but this is just the first phase.
Because our IntraConnect solution should be usable for multiple customers who may have different kinds of accounting and reporting requirements, we had to implement accounting and reporting in a very generic way which fits the majority of the requests we get.
This very generic approach had implications for the various software packages we use because some of them did not log the necessary details and needed to be modified. Furthermore, the accounting file formats have to be open in order to combine them with those of other modules and to process them automatically.
Each night at 00:00 local time the logfiles are rotated and archived
in /var/archive/<modulename>/. This is done by the
rotate script. The reason for rotating at 00:00 is to keep logfiles per
calendar day. Then we gather the various accounting logfiles, preprocess
and send them to the central accounting servers every day where they
are processed further. This way we achieve an enormous data reduction
and only send the necessary accounting information over the expensive,
and often slow, WAN links.
IntraConnect also generates local statistics from the accounting logfiles for group and user accounts, and usage overviews for all services per group and user. This is done by matching the information in the logfiles with the information in the user/group database. The statistics are made available via the web-based GUI, an example can be seen in Fig. 8.
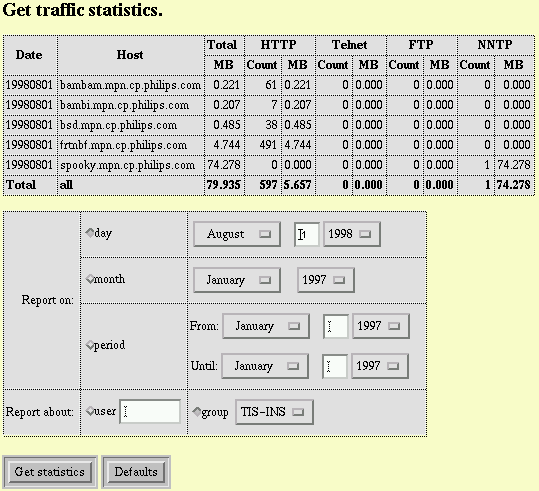
Fig. 8, Traffic statistics example from our local LAN on a very quiet day. Only administrators can request this information, whereas individual users can only request their own information.
The CVS layout is as follows:
htdocs/ docs os/ operating system os/i386-pc-bsdi3.0/ BSD/OS 3.0 OS module os/sparc-sun-solaris2.6/ Solaris 2.6 OS module ... usrconfig/com/philips/cp/mpn/general/ remote configuration, general usrconfig/com/philips/cp/mpn/dns/ dns ... usrdibbs/general/ the general module usrdibbs/admin/ the admin module ... usrdibbs/dns/bin/ dns module, scripts usrdibbs/dns/cgi-bin/ CGI scripts for web GUI usrdibbs/dns/config/ config templates usrdibbs/dns/dist/ original bind 8 distribution usrdibbs/dns/htdocs/ online docs (HTML) ... usrlocal/
usrdibbs/
and CVS files for making the remote configuration modules can be
found below usrconfig/, using reverse-FQDN-based names
like com/philips/cp/mpn/ for each server. This makes managing a
lot of configuration files easy because they are stored in a separate
subtree and in a hierarchical fashion. For example, the DNS root.cache
file, which is the same for philips.com servers, is stored just
once in usrconfig/com/philips/dns/ instead of
multiple times (for each server). A local root.cache file
can still be used and will override any root.cache files from
positions higher in the hierarchy.
Below usrdibbs/<modulename>/ we use bin/ for our
own scripts, config/ for the configuration template files,
lib/ for additional include files, libraries and support
programs (like the mail2news gateway for INN), cgi-bin/ and
htdocs/ for this module's web interface, and finally
dist/ for the original CVS-imported source code.
On an IntraConnect server the scripts from the CVS bin/
directory together with the compiled binaries from the CVS
dist/ directory are installed into
/usr/dibbs/<modulename>/bin/. Files from the CVS
config/ directory are used on the IntraConnect server
together with local and remote configuration files to create the real
configuration files in /usr/dibbs/<modulename>/etc/.
For Solaris we use the same CVS repository on a BSD/OS system and the remote repository mechanism of CVS. Our setup isolates every major OS dependency in separate directories named after the operating system using GNU's config.guess script. Small OS dependencies were solved using conditional statements in our makefiles, also using the config.guess program.
The test target compiles a binary module, installs it in a local temporary directory and creates the module from it. It then installs the module on the distribution server (currently the same machine as the development server) for all test machines. As explained before, the module is stored only once and symlinks are created for the individual machines.
The dist target does the same, but releases the module for all servers including the test servers. The dist target is also used to release configuration modules; because configuration modules are for one server only there is no test target here.
Every module has its own VERSION file which gets automatically updated and committed to the CVS repository by the 'make dist' and 'make test' commands.
Binary module upgrades are done almost weekly for, mostly small, bugfixes and new functionality. Urgent bugfixes are still tested in the standard way but released immediately. Configuration module upgrades are more rare: only when a server has just been installed some configuration fine-tuning is often necessary. Two automated and unattended OS upgrades have been done so far which failed for only one server because it was waiting for its keyboard (the well-known error 'Keyboard error: press F1 to continue' when no keyboard is attached). We operate the IntraConnect machines with only a power cable, one (optionally two) network connections and, if possible, a serial console connection to a terminal server. No monitor, no keyboard, no mouse.
The use of the reverse DNS domain path (like /com/philips/cp/mpn) for the configuration modules and the private directory on the distribution server proved very useful. A module inherits everything available earlier in the reverse DNS domain path. This way we do not need to duplicate information and can store it exactly once.
Because the logfiles are tracked and prioritized in real-time and any messages not filtered explicitly become 'high prio', we are able to create a good filter configuration file per service in a short time. Any new unknown message is evaluated and prioritized depending on the possible impact on the service. The new filter rules are then distributed to all servers with a service upgrade which is just one 'make dist' command on the development/distribution server.
Customers are very pleased with the fact that the user/group administration and authorization for services is done from one GUI. This GUI is set up in such a way that new services can be included very simply. Sample extensions requested by customers included a logfile search facility, so the local administrator can perform some first-line support actions (although understanding logfiles can require in-depth knowledge of the service).
Also on request of our customers we built an accounting/reporting tool for users and groups. Using their usercode and password they can request detailed accounting information up to and including the previous day.
We now operate (multiple) IntraConnect's in New York, Sao Paulo, Sydney, Hong Kong, Barcelona, Paris, Brussel, Vienna, Hamburg, London and Eindhoven. Soon we will add Arlington TX, Singapore, Copenhagen, Milan, Zurich, Taipei and others.
A team of 5 people spent 1.5 man years on technical development and 1.5 man years on management issues. Technical central operation costs 0.5 FTE (Full Time Equivalent). Furthermore we are spending 1 FTE on ongoing development (importing new software package releases, extensions to multi machine servers, etc.). Local administration averages to 0.1 FTE per IntraConnect, which includes first line support.
We extended the master.root file with numbered variable names (for example, DIBBS_IPADDRESS became DIBBS_IPADDRESS_1 and DIBBS_IPADDRESS_2) and added the ethernet MAC address of the primary interface card as the unique machine identifier. Because the master.root file may only be read via no more than two (/bin/sh and perl) include files we were able to hide the fact that multiple machines are involved in those two scripts: on machine number 1 the value of DIBBS_IPADDRESS_1 was copied to DIBBS_IPADDRESS, on machine number 2 the value of DIBBS_IPADDRESS_2 was copied to DIBBS_IPADDRESS and so on. Most of the other scripts could be used unaltered in the multi-machine situation. We were happily surprised that our approach worked out so well.
The only other changes were in the GUI, user/group administration and accounting/reporting. The GUI has been extended so it can find out on which servers a service runs: a hyperlink can now send you to another machine without the user seeing it. The user administration database is replicated from the first 'master' machine to the 'slave' machines by the slave machines when needed, that is, during a service reconfigure. This change was also implemented in one include file, instead of modifying all scripts for all services. Preprocessed logfiles are sent from all servers to the master server which generates the overall accounting and reporting files.
During the implementation of this multi-machine feature we already had a number of servers running. These servers in fact migrated from the old setup to a multi-machine setup with just one server: the one-machine situation can now be considered the minimal multi-machine situation.
Side note: If we find and fix bugs, the fixes are always communicated back to the authors. In the future, our improvements and new features for the freeware packages can be made publicly available too with an Origin disclaimer attached. Note that our IntraConnect framework consisting of Makefiles, sh/perl libraries, installer/service scripts etc. is not publicly available.